google colab에서 개와 고양이 음성 분류를 위해 신경망에 실습해보겠다.
파일은 kaggle 에 있는 개, 고양이 파일로 실습해보았다.
소리 데이터 파일 출처 :
https://www.kaggle.com/datasets/mmoreaux/audio-cats-and-dogs?select=cats_dogs
목차
1. 데이터 로드
코랩에 파일을 올리고 데이터를 로드 시킨다.
아래의 코드 순서는 dog(1~100) —→ cat(101~200) —→ dog (201~300) —→ cat (301~400) 순서이다.
import pandas as pd
import numpy as np
import glob #glob 모듈의 glob 함수는 사용자가 제시한 조건에 맞는 파일명을 리스트 형식으로 반환한다.
# 구글 마운트
from google.colab import drive
drive.mount('/content/drive')
# 음성 데이터의 파일위치와 음성 데이터 이름을 전부 하나의 리스트에 담습니다.
# cats_dogs 폴더 밑에 test 폴더 밑에 test를 dogs로 변경
Test_root = glob.glob('/content/drive/MyDrive/수업/cats_dogs_소리분류/cats_dogs/test')[0]
Train_root = glob.glob('/content/drive/MyDrive/수업/cats_dogs_소리분류/cats_dogs/train')[0]
X_path = glob.glob(Test_root + "/dogs/*") # 테스트 데이터의 개소리 리스트가 X_path에 담김
X_path = X_path + glob.glob(Test_root + "/cats/*") # 위의 리스트 데이터 + 테스트 데이터의
# 고양이 소리 데이터
X_path = X_path + glob.glob(Train_root + "/dog/*") # 위의 리스트 데이터 + 훈련 개소리
X_path = X_path + glob.glob(Train_root + "/cat/*") # 위의 리스트 데이터 + 훈련 고양이 소리
# 들의 위치와 파일명을 이어붙임
print(X_path)
# X_path 에 훈련과 테스트의 모든 개소리와 고양이 소리에 대한 파일의 위치와
# 파일명을 넣어 두었습니다.['/content/drive/MyDrive/아이티윌_수업/cats_dogs_소리분류/cats_dogs/test/dogs/dog_barking_64.wav', '/content/drive/MyDrive/아이티윌_수업/cats_dogs_소리분류/cats_dogs/test/dogs/dog_barking_15.wav', '/content/drive/MyDrive/아이티윌_수업/cats_dogs_소리분류/cats_dogs/test/dogs/dog_barking_91.wav', …
glob 모듈의 glob 함수는 파일명을 리스트 형식으로 변환한다.
파일을 리스트 형식으로 이어붙여 훈련, 테스트 데이터의 모든 파일을 X_path 에 넣어둔다.
2. 라벨링 작업 (vstack)
정답 데이터 코드를 생성한다.
정답 데이터는 vstack 함수를 이용하여 생성한다.
vstack 함수는 행렬 배열을 세로로 append 시키는 함수이다.
# 정답 데이터 생성 코드
import ntpath # 특정 경로에서 파일들을 가져오는 라이브러리
y = np.empty((0, 1, )) # 비어있는 넘파이 어레이 리스트를 만듭니다.
for f in X_path: # 소리 데이터를 하나씩 불러와서 f에 담으면서 반복문을 수행합니다.
if 'cat' in ntpath.basename(f): # f에 들어있는 파일명에 cat이 포함되어있다면
resp = np.array([0]) # [0] # 1차원
resp = resp.reshape(1, 1, ) # [[0]] # 2차원
y = np.vstack((y, resp)) # 배열을 세로로 결합 #numpy용 append
elif 'dog' in ntpath.basename(f): # f에 들어있는 파일명에 dog가 포함되어있다면
resp = np.array([1]) # [1]
resp = resp.reshape(1, 1, ) #[[1]]
y = np.vstack((y, resp)) # 계속 append
# X_path 순서 : dog--> cat --> dog --> cat
# # 이 정답 데이터 코드 생성하려면 파일명에 cat_ , 혹은 dog_ 이름이 들어가 있어야한다.
print (y)[[1.]
[1.]
[1.]
...
[0.]
[0.]
[0.]
[0.]]
위에서 파일명에 dog, cat이 들어가있으므로 dog가들어가면 [1] 로, cat이 들어가있으면 [0]으로 빈 numpy array 리스트에 append 시킨다.
3. 사이킷런을 이용해서 훈련과 테스트로 분리
처음 폴더 test,train에 들어있는 것은 무시하고 전체 데이터 X_path 에 들어있는 걸로 훈련, 테스트 데이터로 나누겠다.
(훈련 75%, 테스트 25%로 나눕니다.)
# 사이킷런을 이용해서 전체 데이터 277개를 훈련과 테스트 데이터로 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_path, y, test_size=0.25, random_state=42)4. 소리를 숫자로 변환해주는 함수 생성(librosa 라이브러리 이용)
소리를 숫자로 변환해주는 librosa 라이브러리로 함수를 생성한다.
librosa_read_wav_files 함수를 생성하여
음원 파일을 숫자로 변환하고, 진폭과 sample rate 중 진폭만 출력하는 함수를 생성한다.
# 소리에서 숫자값을 뽑아 리턴하는 함수 생성
import librosa #음원 데이터를 분석해주는 아주 고마운 라이브러리
# https://hyongdoc.tistory.com/401 음성 파일 로드하는 부분 설명 잘한 블러그
def librosa_read_wav_files(wav_files):
if not isinstance(wav_files, list): # 불러온 파일의 요소가 list가 아니라면
# https://brownbears.tistory.com/155 isinstance(1, int) # 1이 int형인지 알아봅니다. 결과는 True 입니다.
wav_files = [wav_files] # 리스트로 변환
return [librosa.load(f)[0] for f in wav_files] # 진폭과 샘플레이트중 진폭만 담는다.
# 음원의 숫자값 , sr값 = librosa.load('/음원의 위치/음원명')
# librosa.load(f)[0] : 음원의 숫자값인 진폭만 가져오겠다.5. 음원에서 sample rate 숫자값인 진폭을 가져오기
오리지널 음원을 위에서 만든 librosa_read_wav_files 함수에 넣어 진폭만 변환한다.
sample rate (아날로그 소리를 디지털 소리로 표현한 디지털 정보)
# 훈련 데이터 중 하나의 소리에서 해당 동물의 주파수대 번호(sr값) 추출
wav_rate = librosa.load(X_train[0])[1] # 동물 소리 한개의 sample rate를 wav_rate에 담음
# print(wav_rate) # 22050
# sr값이 동물과 사람이 서로 틀리고 개와 고양이는 비슷하지만,
# 개와 새는 서로 sr 값의 범위가 다릅니다.
# 그래서 개, 고양이 sr 값을 따로 따로 따지 않고, 하나만 땄다.
# librosa_read_wav_files() :음원 숫자값(진폭) 가져오는 함수
X_train = librosa_read_wav_files(X_train) # 소리 데이터를 숫자로 변경한 값 (훈련)
X_test = librosa_read_wav_files(X_test) # 소리 데이터를 숫자로 변경한 값 (테스트)
print(len(X_train))
print(len(X_test))
print(X_train[0]) # 5초도 안되는 개소리를 숫자로 변경되었는지 출력6. 음성 시각화
위의 소리를 숫자로 변경된 것을 시각화해본다.
# 개 음성과 고양이 음성을 각각 시각화
import matplotlib.pyplot as plt
fig, axs = plt.subplots(2, 2, figsize=(16,7))
axs[0][0].plot(X_train[1]) # 개
axs[0][1].plot(X_train[0]) # 개
axs[1][0].plot(X_train[6]) # 고양이
axs[1][1].plot(X_train[21]) # 고양이
plt.show()
7. MFCC 작업 수행하는 함수 생성
음성에서 feature 을 추출하는 MFCC 작업을 하는 함수를 생성한다
# 음성에서 특징을 추출하는 MFCC 작업을 수행하는 함수
def extract_features(audio_samples, sample_rate): # 숫자값, 주파수 대역 숫자
extracted_features = np.empty((0, 41, )) # 비어있는 numpy list를 만드는데 41개의 feature을 담을거라
# 리스트에 41개의 비어있는 자리를 준비
#(1,41) 은 아니고 그냥 41개의 값을 받을 메모리를 할당하겠다는 뜻
if not isinstance(audio_samples, list):# 리스트가 아니라면
audio_samples = [audio_samples] # 리스트화 해라
for sample in audio_samples:
# 신경망에 넣은 음성에서 추출한 특징 41개의 데이터 중에서 zero_crossing 데이터를 준비
# 이 데이터가 저주파 데이터인지 고주파 데이터인지를 쉽게 확인할 수 있는 정보
zero_cross_feat = librosa.feature.zero_crossing_rate(sample).mean() # 신호의 부드러움을 측정하거나 유성음과 무성음 부분을 분리할 때 사용하
# 주파수 스펙트럼 데이터 40개 준비
mfccs = librosa.feature.mfcc(y=sample, sr=sample_rate, n_mfcc=40) # https://youdaeng-com.tistory.com/5
mfccsscaled = np.mean(mfccs.T,axis=0) # 각 주파수별 평균값을 구합니다. #https://stackoverflow.com/questions/36182697/why-does-librosa-librosa-feature-mfcc-spit-out-a-2d-array
mfccsscaled = np.append(mfccsscaled, zero_cross_feat)
mfccsscaled = mfccsscaled.reshape(1, 41, ) # 41개의 리스트 요소를 담는 numpy array 구성
# 비어있는 넘파이 어레이 extracted_features에 41개의 요소를 추가합니다.
extracted_features = np.vstack((extracted_features, mfccsscaled)) # 주파수 스펙트럼 데이터 40개 + zoro_crossing 데이터 1개
return extracted_features# wave_rate 에 개과 고양이에 속하는 주파수 영역을 주어야 합니다.
# 사람의 목소리는 대부분 16000Hz 안에 포함된다고 합니다
X_train_features = extract_features(X_train, wav_rate)
X_test_features = extract_features(X_test, wav_rate)
print(len(X_train_features)) # 각각 41개씩 207개 생성
print(len(X_test_features)) # 각각 41개씩 70개 생성8. 텐써플로우 신경망 모델 구성 준비 작업(모듈 불러오기, 원핫 인코딩)
텐써플로우로 신경망을 구성할 때 필요한 라이브러리 불러오고,
훈련 데이터와 테스트 데이터에 대한 원핫 인코딩을 수행한다.
# 텐써 플로우로 신경망을 구성할 준비 작업
from keras import layers
from keras import models
from keras import optimizers
from keras import losses
from keras.callbacks import ModelCheckpoint,EarlyStopping
from tensorflow.keras.utils import to_categorical# 원핫 인코딩
train_labels = to_categorical(y_train) # 훈련 데이터에대한 원핫 인코딩 수행
test_labels = to_categorical(y_test) # 테스트 데이터에 대한 원핫 인코딩 수행
print(test_labels)[[1. 0.]
[0. 1.]
[1. 0.]
…
[0. 1.]
[0. 1.]
[1. 0.]]
9. 신경망 모델 구성
(1) 모델 구성
이번 모델은 완전 연결계층만을 하여 실습해보겠다
이미지의 feature을 잘 잡으려면 cnn이 필요하지만 그냥 소리데이터이므로 cnn을 안쓰고 해보겠다.
# 모델 구성 (완전 연결 계층만 있다)
# 이미지의 특징을 잘 잡으려면 cnn이 필요. 그런데 이번에는 그냥 소리 데이터이므로
# 굳이 cnn을 안써도 됩니다.
model = models.Sequential()
model.add(layers.Dense(100, activation = 'relu', input_shape = (41, ))) # 1층 (0층, 1층)
model.add(layers.Dense(50, activation = 'relu')) # 2층
model.add(layers.Dense(2, activation = 'softmax')) # 3층
model.summary()Model: "sequential" ____________________________________
Layer (type) Output Shape Param #
==========================================
dense (Dense) (None, 100) 4200
dense_1 (Dense) (None, 50) 5050
dense_2 (Dense) (None, 2) 102
========================================================
Total params: 9,352
Trainable params: 9,352
Non-trainable params: 0
________________________________________________________
best_model_weights = './base.model' # 생성된 모델 저장할 이름 지정 # ./ : 현재디렉토리 밑에 저장
# https://deep-deep-deep.tistory.com/53
# 얼리스탑 기능을 구현
checkpoint = ModelCheckpoint(
best_model_weights, # 모델의 저장 위치
monitor='val_accuracy', # 모델이 저장되는 기준 값: 테스트 데이터의 정학도
verbose=1, # 저장되었다는 화면 표시
save_best_only=True, # monitor되고 있는 값을 기준으로 가장 좋은 값으로 모델이 저장됨
mode='max', # min, max, auto
save_weights_only=False, # False인 경우, 모델 레이어 및 weights 모두 저장
period=1 # checkpoint를 저장할 간격(에폭수)
)
estop = EarlyStopping(monitor = 'val_accuracy', patience = 20, verbose = 1)
# val_acc는 테스트 데이터의 정확도로 모니터링을 하는데
# patience=20 은 20번의 테스트 데이터의 정확도의 향상이 없다면 그냥 멈춰라
# verbose = 1 : 진행과정 화면 표시
# 위에서 만든 checkpoint 와 얼리스탑을 리스트로 구성하여 callbacks 에 넣는다
callbacks = [checkpoint, estop]
# 모델 설정
model.compile(optimizer='adam',
loss=losses.categorical_crossentropy,
metrics=['accuracy'])
콜백 기능을 넣어서 20번의 테스트 데이터의 정확도 향상이 없다면 멈추게 했다.
그리고 모델 학습은
adam을 사용했다.
(2) 모델 훈련
# 모델 훈련
history = model.fit(
X_train_features, # 훈련 데이터
train_labels, # 훈련 데이터의 라벨(정답)
validation_data=(X_test_features,test_labels), # 테스트 데이터와 정답
epochs = 200,
verbose = 1,
callbacks=callbacks, # 얼리스탑 기능 구현을 위해서 위에서 만든 callbacks 지정
)(3) 훈련 모델 시각화해보기
# 훈련 모델 시각화
print(history.history.keys())
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc)+1)
plt.plot(epochs, acc, 'b', label = "training accuracy")
plt.plot(epochs, val_acc, 'r', label = "validation accuracy")
plt.title('Training and validation accuracy')
plt.legend()
plt.show()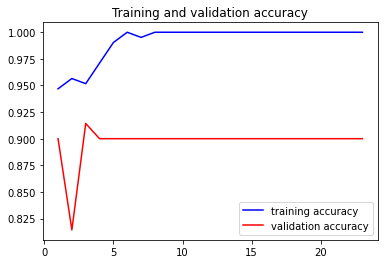
(4) 훈련 모델 저장
# 모델 저장
model.save_weights('model_wieghts.h5') # 모델 가중치
model.save('model_keras.h5') # 모델 자체를 저장(5) 잘 맞추는지 확인
# 훈련한 모델로 잘 맞추는지 확인
# 테스트 데이터 6번 데이터로 확인
import IPython.display as ipd
nr_to_predict = 6
pred = model.predict(X_test_features[nr_to_predict].reshape(1, 41,))
print("Cat: {} Dog: {}".format(pred[0][0], pred[0][1]))
if (y_test[nr_to_predict] == 0):
print ("This is a cat meowing")
else:
print ("This is a dog barking")
plt.plot(X_test_features[nr_to_predict])
ipd.Audio(X_test[nr_to_predict], rate=wav_rate)1/1 [==============================] - 0s 74ms/step Cat: 0.00020996473904233426 Dog: 0.9997900128364563
This is a dog barking
강아지로 맞췄다.
'딥러닝' 카테고리의 다른 글
| [GAN] 인공지능으로 화장시키기 (0) | 2022.11.11 |
|---|---|
| 밑바닥부터 시작하는 딥러닝 8장 -2. 사물검출(object detection) (0) | 2022.10.18 |
| 밑바닥부터 시작하는 딥러닝 8장. 딥러닝의 역사와 기술들 (1) | 2022.10.18 |
| 밑바닥부터 시작하는 딥러닝 7장 CNN (1) | 2022.10.16 |
| 밑바닥부터 시작하는 딥러닝 6장-1. 언더피팅을 방지하는 방법들 (0) | 2022.10.13 |


