출처: 밑바닥부터 시작하는 딥러닝
목차
1. LeNet - CNN 시초 신경망
LeNet 은 손글시 숫자를 인식하는 신경망으로 1998년에 제안되었다.
CNN 알고리즘의 시초 신경망이다.
MNIST 데이터를 만든 얀루큰 교수님에 의해 개발됨.
지금은 28x28 사이즈를 사용하는데 그 당시에는 32x32 사이즈로 신경망에 넣었다.
설계도 :
이미지(32x32) ——> conv —→ maxpooling —→ conv —→ maxpooling —→
fully connected1 —→ fully connected2 —→ fully connected3 —→ outpu
2. VGG 신경망
1994년 고전 CNN —————————————————————> 2014년 영국 옥스포드 대학교
LeNet 신경망 ————————————————————————> vgg 신경망합성곱 계층과 풀링 계층으로 구성되는 기본적인 CNN
비중 있는 층(합성곱 계층, 완전연결 계층)을 모두 16층(혹은 19층)으로 심화함.
이미지를 잘 분류하는 신경망을 어떻게 설계해야할까? 라는 고민들을 사람들이 많이 했었다. 그리고 가장 잘 분류하는 신경망 설계도를 만들었는데 그 대표적인데 바로 vgg 신경망과 구글에서 만든 inception 신경망이다.
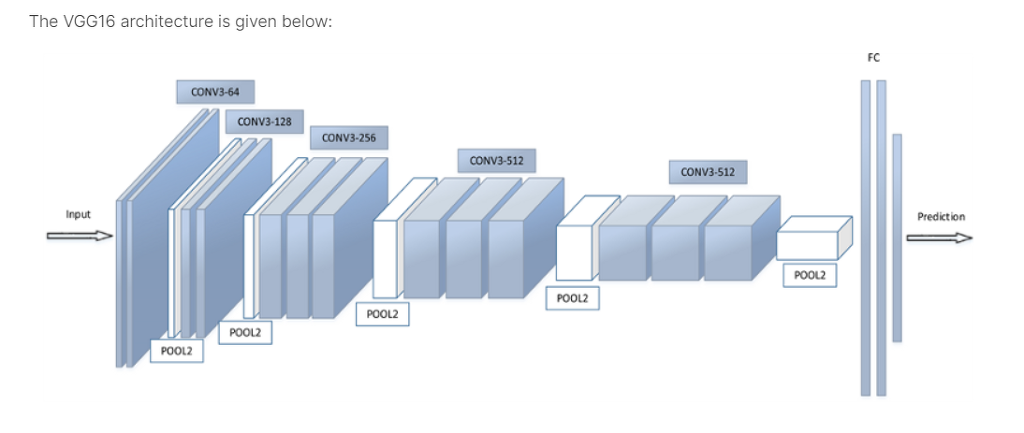
3*3의 작은 필터를 사용한 합성곱 계층을 연속으로 거친다.
합성곱 계층을 2~4회 연속으로 풀링 계층을 두어 크기를 절반으로 줄이는 처리를 반복하고 마지막에는 완전연결 계층을 통과시켜 결과를 출력한다.
텐써플로우에 VGG16 설계도 코드가 내장되어있다.
# VGG16 설계도 가져오기
from tensorflow.keras.applications import VGG16
vgg16= VGG16(weights= 'imagenet', input_shape=(32,32,3), include_top=False)#코드 설명
weights='imagenet' —> 이미지넷 대회에서 준우승한 그 가중치를 사용하겠다.
(설계도는 당연히 가져오고 가중치도 가져오겠다)
weights=’None' —> 이미지넷 대회에서 준우승한 그 가중치를 사용 안하겠다.
(설계도만 가져오고 그냥 처음부터 학습시키겠다)
include_top=False —> include_top 은 완전 연결계층의 모델의 분류기를 내가 직접 기술할지 말지를 결정합니다. False 로 하게 되면 내가 직접 완전 연결계층을 짜겠다.
3. cifar10 을 VGG 신경망으로 학습시키기 (텐써플로우)
텐써플로우 내장 데이터인 cifar10 을 불러와서 VGG16모델에 학습시키겠다.
실제 이미지넷 대회에서 사용한 신경망 설계도는 클래스가 1000개이다. 하지만 지금은 10개의 이미지만 분류하므로
완전 연결계층을 직접 구현하였다.
# cifar10 을 vgg 신경망으로 분류하기
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense,Dropout, Conv2D, MaxPooling2D, Flatten,BatchNormalization, Activation # CNN, 완전 연결계층을 구성하기 위한 모듈
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
import numpy as np
# 2. VGG16 설계도 가져오기
from tensorflow.keras.applications import VGG16
vgg16= VGG16(weights= 'imagenet', input_shape=(32,32,3), include_top=False)
vgg16.summary()
# 2-(1) vgg16 신경망을 동결 시켰을 때 (그대로 쓰겠다)
#for layer in vgg16.layers[:] : #vgg 신경망의 모든 것을 다 가져오겠다.
# layer.trainable = False # False 는 동결 (따로 학습을 안하고 vgg 신경망 학습 동결시켜 쓰겠다)
# 2-(2) vgg16 신경망을 동결 시키지 않았을 때
for layer in vgg16.layers[:] : #vgg 신경망의 모든 것을 다 가져오겠다.
layer.trainable = True # True 는 동결해제 (즉, 훈련가능한 상태로 냅둔다) # default
vgg16.summary()
#3. cifar10 데이터 가져오기
tf.random.set_seed(777)
(x_train,y_train),(x_test,y_test) = cifar10.load_data() # cifar 데이터 로드
print(x_train.shape) # (60000, 28, 28)
print(x_test.shape) # (10000, 28, 28)
# 설명: 위의 결과는 색조를 나타내는 차원이 없습니다.
# 그래서 다음과 같이 색조를 나타내는 차원을 추가주겠금 reshape 를 해줘야합니다.
# (60000, 32, 32) ----> (60000, 32, 32, 3)
# (10000, 32, 32) ----> (10000, 32, 32, 3)
# 3차원을 4차원으로 변경해주되 안의 요소(픽셀)의 갯수는 동일해야합니다.
# 3차원(60000*28*28) ------> 4차원( 60000*28*28*1) 로 갯수는 동일합니다
x_train = x_train.reshape(-1, 32, 32, 3) # -1의 의미는 학습데이터는 갯수만큼 알아서 하고 4차원으로 변경해라
x_test = x_test.reshape(-1, 32, 32, 3 )
print(x_train.shape) # (60000, 28, 28, 1)
print(x_test.shape) # (10000, 28, 28, 1)
# 4. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 5. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 6. 모델을 구성합니다.
model = Sequential()
model.add(vgg16) # vgg16 모델 사용
# 완전 연결계층 직접 구현
model.add( Flatten() )
model.add( Dense(256) )
model.add(BatchNormalization())
model.add(Dropout(0.4))
model.add(Activation('relu'))
model.add( Dense(256) )
model.add(BatchNormalization())
model.add(Dropout(0.4))
model.add(Activation('relu'))
model.add(Dense(10,activation='softmax'))
model.summary()
# 이미지넷 대회에서의 vgg 신경망의 출력층의 뉴련의 갯수는 1000개
# 그런데 우리는 cifar10 데이터로 10개의 클래스를 분류할 거라서 include_top=False 로 두고
# 완전 연결계층을 우리 손으로 직접 만듦
# 7. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='adam',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
"""
# 얼리스탑 기능 추가
class MyThresholdCallback(tf.keras.callbacks.Callback):
def __init__(self, threshold):
super(MyThresholdCallback, self).__init__()
self.threshold = threshold
def on_epoch_end(self, epoch, logs=None):
val_acc = logs["val_acc"]
if val_acc >= self.threshold:
self.model.stop_training = True
#검증 데이터의 정확도가 80% 넘으면 조기중단하게 설정
callbacks = MyThresholdCallback(threshold=0.8)
"""
#8. 모델을 훈련시킵니다.
history = model.fit(x_train, y_train,
epochs = 100, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 9.모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test,y_test)
train_acc_list=history.history['acc']
train_acc_list
test_acc_list=history.history['val_acc']
test_acc_list
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()여기서 동결의 의미가 중요하다.
finetuning 은 조금 더 찾아보기
4. VGG 외에 다른 유명한 신경망 설계도
[1] GoogleNet
기본적으로 기존의 CNN과 다르지 않지만 세로방향 깊이 뿐 아니라 가로 방향도 깊다는 점이 특징이다.
GoogleNet에는 가로 방향에 폭이 있고, 이를 인셉션 구조라고 한다.

#텐써플로우 코드
from tensorflow.keras.applications import *
model=Xception(weights='imagenet',input_shape=(32,32,3), include_top=False)
[2] MS 사에서 만든 ResNet 설계도
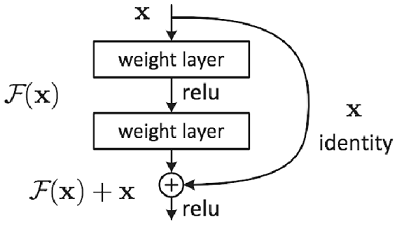
스킵연결(skip connection): 층의 깊이에 비례해 성능을 향상시킨다.입력 데이터를 합성곱 계층(weight layer)을 건너뛰어 출력에 바로 더하는 구조역전파 때 스킵 연결이 신호 감쇠를 막아주기 때문에 층이 깊어져도 학습을 효율적으로 할 수 있다.
from tensorflow.keras.applications import *
resnet = ResNet50( weights = 'imagenet', input_shape(32,32,3), include_top=False)[3] mobilenet
가벼우면서도 성능이 아주 좋은 신경망이다.
from tensorflow.keras.applications import *
mobile = MobileNet( weights = 'imagenet', input_shape(32,32,3), include_top=False)
'딥러닝' 카테고리의 다른 글
| 개, 고양이 음성 분류 신경망 실습 (2) | 2022.10.25 |
|---|---|
| 밑바닥부터 시작하는 딥러닝 8장 -2. 사물검출(object detection) (0) | 2022.10.18 |
| 밑바닥부터 시작하는 딥러닝 7장 CNN (1) | 2022.10.16 |
| 밑바닥부터 시작하는 딥러닝 6장-1. 언더피팅을 방지하는 방법들 (0) | 2022.10.13 |
| 밑바닥부터 시작하는 딥러닝 5장 13 소프트맥스함수 with 오차함수 계층 구현하기 (1) | 2022.10.13 |

