목차
1. 나이브 베이즈란
- 머신러닝의 종류 중 지도학습에 해당( 정답이 있는 데이터를 기계가 학습 )
- 분류 : knn (3장), naivebayes(4장)
- 독립변수들의 데이터가 전부 숫자면 knn 을 사용하고, 독립변수들의 데이터가 전부 문자면 naivebayes를 사용
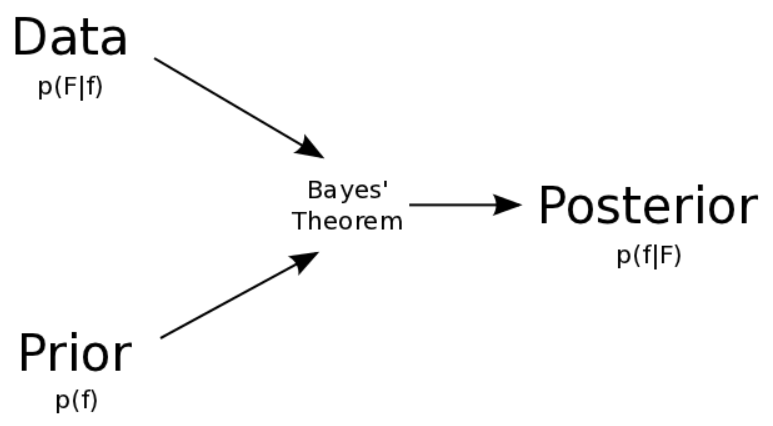
사전확률과 데이터를 통해 사후확률을 예측하는 것
- 나이브 베이즈 알고리즘이 사용되는 분야
- 스팸 이메일 필터링과 같은 텍스트 분류
- 컴퓨터 네트워크에서 발견되는 침입이나 비정상적인 행위 탐지
- 일련의 관찰된 증상에 대한 의학적 질병 진단 (분류)
2. 나이브베이즈 이론 설명
[1] 나이브베이즈 알고리즘 개념
사전확률을 임의로 정하고, 데이터를 이용해 사전확률을 업데이트하여 사후확률을 생성한다.
예를 들어 메시지가 스팸인지 예측하려고 한다면
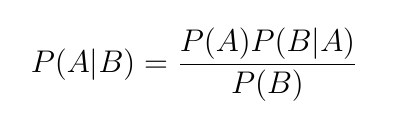
여기서 우리가 알고자 하는 건
P(A|B) : 사후 확률 (posteriori probability),
즉 비아그라 메시지가 있을 때 메시지가 스팸인지 알아보려고 한다.
이때 우리는 사전확률과 데이터를 가지고 사후확률을 예측한다.
- P(A) : 사전 확률 (prior probability) :
- 특정 사건이 일어나기 전의 확률 ,
- 여기서는 스팸인 확률
우도(likelihood) : P(B|A) :
특정사건이 발생했다는 조건 하에 다른 사건이 발생할 확률
(즉, 스팸인 경우 비아그라 메세지가 있는 확률)
P(비아그라|스팸)
주변우도(likelihodd) : p(비아그라)
P(비아그라 | 스팸 ) * P(스팸)
P(스팸 | 비아그라) = ---------------------------------------
P(비아그라)
분류를 하기 위한 첫 스텝은 Feature와 Label을 파악해야한다.
Label은 우리가 원하는 분류 결과이다. 스팸 메일을 예로 들면 스팸 메일인지 아닌지의 여부가 Label이다.
이 Label 결과에 영항을 주는 요소가 Feature입니다. 역시 스팸 메일을 예로 들면, feature은 스팸 메일의 제목 및 내용에 기재된 광고성 단어, 비속어, 성적 용어 등입니다.
Feature -> 광고성 단어 개수, 비속어 개수, 성적 용어 개수 등... (각각이 하나의 Feature이며, 하나의 분류 모델에는 여러 개의 Feature가 있음)
Label -> 스팸 메일인 경우 Label = 1, 스팸 메일이 아닌 경우 Label = 0
[2] 나이브 베이즈 알고리즘 조건
- 나이브 베이즈 알고리즘은 데이터에 대해 약간 ‘순진한(naive) 가정 ‘ 을 하고 있다.
- 특히 나이브 베이즈는 데이터셋(feature)의 모든 특징이 동등하게 중요하고 독립적이라고 가정
- 나이브 베이즈가 잘못된 가정에도 불구하고 잘 작동하는 정확한 이유는 많은 추측이 이루어지고 있다.
3. 라플라스 추정기(P159)
P(비아그라|스팸) * P(돈 | 스팸) * P(식료품|스팸) * P(구독취소|스팸) = 0
4/20 10/20 0/20 12/20
분자의 요소 하나라 0이면 전체 0이 되면서 스팸의 우도가 0이 되어버린다.
그래서 분자와 분모 각각 1씩 더해주는 것이 라플라스 추정기 이다.
P(비아그라|스팸) * P(돈 | 스팸) * P(식료품|스팸) * P(구독취소|스팸) * P(스팸) = 0.0004
5/24 11/24 1/24 13/24 20/100
4. 파이썬 나이브베이즈 모델 코드
# GqussianNB 에 있는 라플라스 정리 사용
#from sklearn.naive_bayes import BernoulliNB
# model = BernoulliNB(alpha= 0.001)
from sklearn.naive_bayes import GaussianNB
model2 = GaussianNB(var_smoothing=0.001)
model2.fit(x_train,y_train)
result2= model2.predict(x_test)정확도 확인
# 정확도 확인
sum(result2==y_test)/len(y_test)*100 # 99.50769230769231FN 값 확인
# FN 값 확인
from sklearn.metrics import confusion_matrix
tn,fp,fn,tp = confusion_matrix(y_test, result2).ravel()
print(tn,fp,fn,tp) # 814 6 2 803'머신러닝' 카테고리의 다른 글
| 의사결정트리 이론 (1) | 2022.10.22 |
|---|---|
| KNN 알고리즘 (3) | 2022.10.08 |
| 머신러닝과 딥러닝 알고리즘 (1) | 2022.10.08 |
| 인공지능, 머신러닝, 딥러닝 개념 (0) | 2022.10.08 |



